Processing Basics



Processing Basics |
|
|
Our aim in developing Mnova has been to make the opening, processing, handling, analysis, saving and printing of NMR data simpler than it has ever been before, so that even the NMR novice can enjoy the software and obtain excellent results from the very start.
Mnova introduces a brand new NMR data processing paradigm; when a raw, unprocessed spectrum (FID) is opened, you will get the fully processed spectrum instantaneously.
This new concept consists of two fundamental points:
1.Automatic File Format Recognition: Once you select the FID, Mnova will automatically identify its origin (e.g. Varian, Bruker, Jeol, etc). 2.Fully Automatic Processing: Once the FID is opened Mnova will automatically and optimally process it using the information it discovered in Part 1, so you do not need to bother with processing details.
The two steps outlined above will successfully process most NMR data. However, if you are not completely satisfied with the result you can, at anytime, reprocess using your own choice of processing parameters, changing or adjusting the window function, the FT, the phasing and baseline correction to meet your requirements.
With this scheme, processing of 1D and 2D spectra is essentially identical as you will see in the following two tutorials:
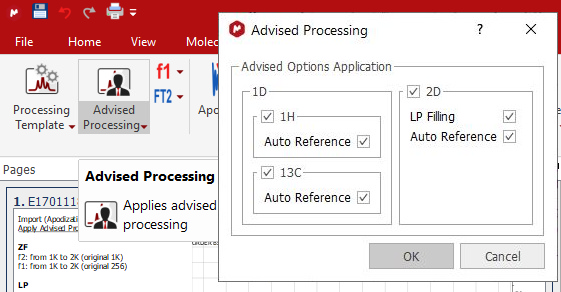
There is also an 'Advised processing' feature which will apply a suggested processing with the option to automatic reference the spectra and to apply a Linear Prediction:
For 1H it will apply a Stanning apodization of 8.0, a three fold Zero Filling, 'Regions Analysis' phase correction a Bernstein polynomial (order 3) baseline correction. For 13C datasets, it will include an exponential apodization of 2.0 Hz (on top of the Stanning), 'Regions Analysis' phase correction and a Bernstein polynomial (order 3) baseline correction.
For 2D, it will apply a Zero Filling along F2 with a maximum factor of 2 and an exponential apodization of 2.0 Hz and Stanning 4.0 and a 'Fit to Highest Intensity' For F1 it will apply a Sine Square 90º (first point: 0.5) apodization and a ZF (up tp 3 times). Magnitude phase correction (only in f2) will be also applied in case of HMBC spectra an in other 2D spectra where FT is None. In other cases, Regions phase correction will be applied in both F1 and F2.
For homonuclear 2D NMR experiments, the advised processing will set the size of the F1 dimension equal to the size along the direct dimension (the goal is to get square matrices so that if symmetrization is needed, this would make the process more efficient so that no interpolation will be needed). |