Peak Picking Options



Peak Picking Options |
|
|
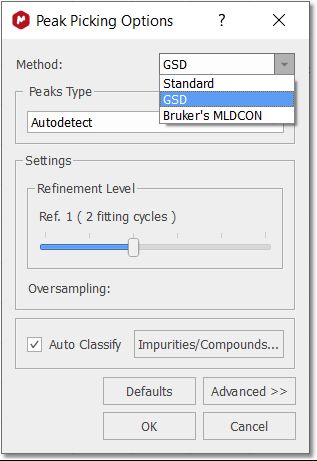
Mnova has three Peak Picking algorithms: GSD (by default, with global spectral deconvolution and slower than the Std), Standard (without deconvolution, faster than GSD) and Bruker´s MLDCON (for Bruker datasets):
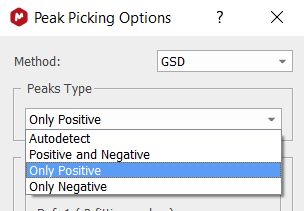
You can select the Peaks Type from the scroll down menu:
The Autodetect mode will let Mnova to decide regarding the experiment type, so if for example you have a 2D NMR spectrum acquired in magnitude mode, Mnova will only search for positive peaks. However, if you have a DEPT dataset, it will look for both positive and negative peaks. The user can also force the search to only positive, only negative or both type of peaks.
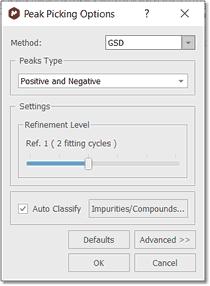
GSD Peak Picking options: The Peak Picking based on GSD (Global Spectral Deconvolution) will have these options:
GSD has different operational levels, ranging from a very fast but inaccurate method to slower but much more accurate levels. In addition, GSD makes it possible the automatic recognition of solvent peaks, impurities, etc. We recommend to use a GSD level of 1 (flash) or 2. From this menu we can set the Refinement Level (number of cycles) and the 'Auto Classify' of the GSD peaks. Clicking on the 'Defaults' button will restore the default settings from the registry. The 'Refinement Level' will be the number of GSD fitting cycles applied over the spectrum. For example if you select 2 cycles, that means that the program will apply a GSD to your original spectrum and then another to the deconvoluted spectrum. GSD has different operational levels, ranging from a very fast but inaccurate method to slower but much more accurate levels. We recommend to use a GSD level of 1 (flash) or 2. 'Auto Classify': the program will try to identify the type of each signal of the spectrum (compound, solvent, impurity, etc). This information will appear in the 'Type' column of the Peaks table. This feature should be used only with GSD (and not with the Standard method). Clicking on the 'Advanced' button will allow you to select the 'Quantitative GSD' algorithm which generates less residuals in the fitting and better area values. Standard Peak Picking options: This algorithm is much faster than GSD, but it does not include deconvolution.
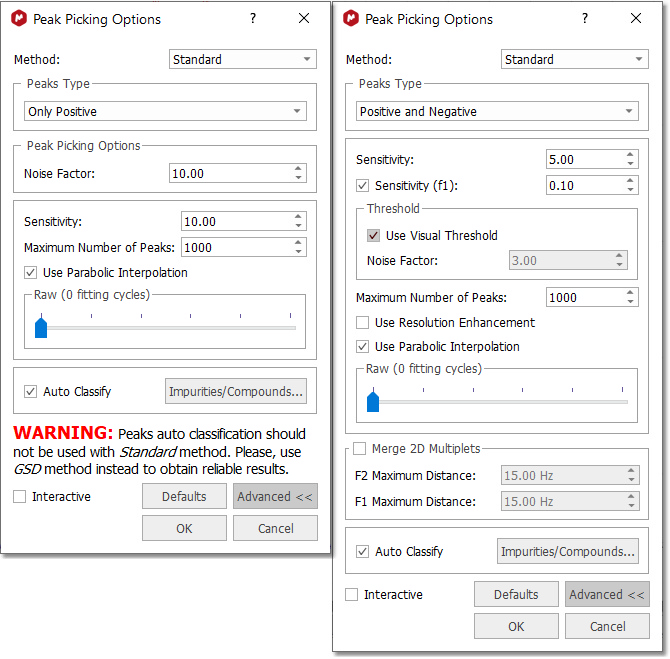
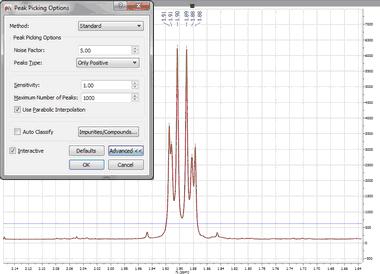
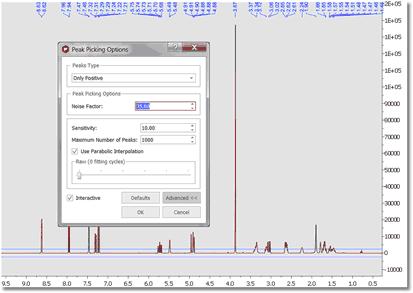
A series of options can be controlled on the 'Peak Picking Options' dialog box, which can be accessed via the Peak Picking scroll menu. The user can choose the 'Noise Factor' (with visual threshold for 2D) and the 'peaks type'. Clicking on the 'Advanced' button, will allow you to change the 'sensitivity' factor (the higher the value, the less peaks will be picked), maximum number of peaks, whether to 'use parabolic interpolation', merging options for 2D multiplets. All these options can be evaluated interactively, so that their results can be viewed on screen in real time, by making sure the 'Interactive' box is selected.
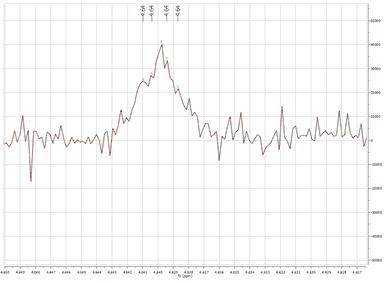
- Sensitivity: it is basically a kind of smoothing parameter. For example, in noisy spectra, large values of this parameter will smooth the spectrum in the background so that less peaks will be detected. By default, this value will be 1 which means that the program will try to find the maximum number of peaks in the spectrum. This is the recommended value for routine 1D spectra. The sensitivity factor is indeed being used by the program and its main application is to avoid the detection of too many peaks in noise spectra. As we said above, this option can be considered as a smoothing parameter which is somehow applied before the peak picking algorithm is applied. For instance, if you have a very noise peak with a lot of local extrema caused by the random fluctuations of the noise, the peak picking algorithm could find just too many peaks which do not correspond to real peaks, just noise local maxima/minima. In order to avoid that situation, the sensitivity factor can be increased in such a way that the peak is smoothed on the fly and ideally, only the real peak would be detected. For example, this is what happens with a very low value for the sensitivity in a noisy spectrum:
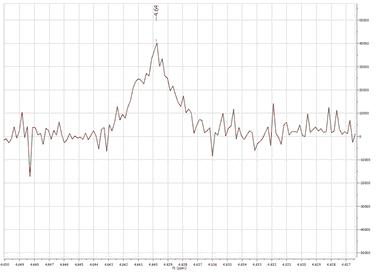
And this is the result when a higher value is used:
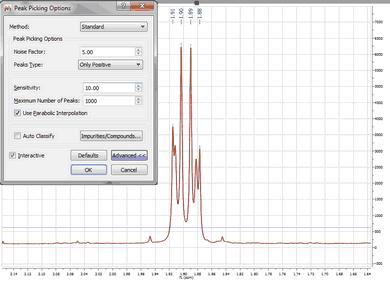
It is shown below, how this sensitivity factor is being used by the program by opening a 1H-NMR spectrum of strychnine. First you will see the result with sensitivity = 1 (BTW, it’s important to realize that the sensitivity factor can be lower than 1. The lower the value, the higher the resolving power of the algorithm): So you can appreciate that with sensitivity =1 all peaks have been detected. Now let’s increase the value to 10. This is the result:
You can see that only 4 peaks have been detected whilst 2 less resolved peaks are missing now. - Noise Factor: it is a kind of intensity threshold. The program will automatically calculate the noise value of the spectrum. This noise value is then multiplied by the noise factor. After running the peak picking algorithm, peaks smaller than the noise value multiplied by the noise factor will be rejected. The program shows this vertical threshold as two horizontal lines in the spectrum, as you can see in the picture below:
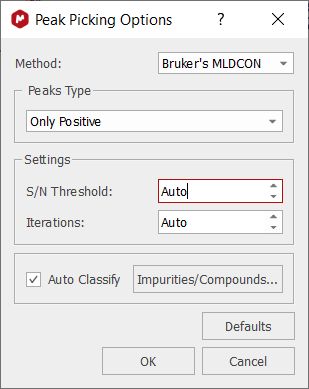
Bruker's MLDCON This algorithm can be used for any Bruker 1D spectra (positive and negative peaks). It requires to have a Java virtual machine installed. You can select the signal to noise threshold and the number of iterations:
|